Support Vector Machines
The Champions of Classification

Introduction
In the realm of machine learning, classification reigns supreme. It's all about sorting data points into distinct categories, whether it's spam or not-spam emails, cat pictures or dog pictures, or tumors in medical scans. And when it comes to classification tasks, there's a powerful algorithm that often emerges victorious: the Support Vector Machine (SVM).
What Makes SVMs Special?
Imagine you have a bunch of data points scattered on a graph, representing different categories. SVMs aim to find the best dividing line, or hyperplane, that separates these categories with the largest margin. This margin is essentially the distance between the hyperplane and the closest data points from each category, called support vectors.
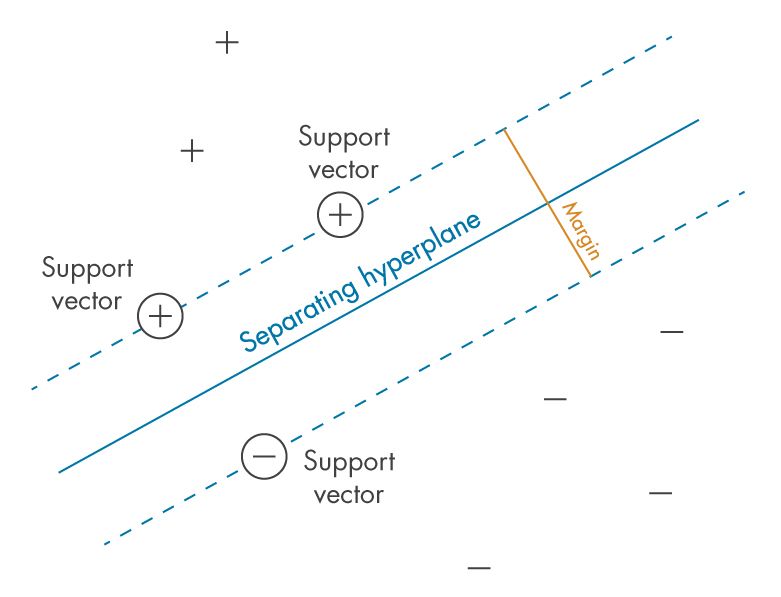
Why is a Big Margin Important?
A large margin signifies a clear distinction between the categories. The wider the gap, the less likely the SVM is to misclassify new data points that fall close to the dividing line. This translates to better overall performance and a reduced risk of overfitting, a common pitfall in machine learning.
Beyond the Binary: SVMs for All
While the classic SVM tackles binary classification (think spam/not-spam), its versatility shines through. By employing clever tricks like the kernel trick, SVMs can be adapted for more complex scenarios:
Multi-class classification: Distinguish between more than two categories, like classifying handwritten digits (0-9).
Non-linear classification: Handle data that isn't neatly separable with a straight line. Imagine separating crescent-shaped data clusters!
The Advantages of Using SVMs
Effective in high dimensions: SVMs can handle data with many features, making them suitable for complex problems.
Memory efficient: They only rely on the support vectors to define the decision boundary, leading to efficient memory usage.
Strong theoretical foundation: SVMs are built on a solid mathematical framework, ensuring their effectiveness and generalizability.

Where Can You Find SVMs in Action?
SVMs have a wide range of applications:
Image recognition: Classifying objects in images, like identifying faces or self-driving car applications.
Text classification: Categorizing emails, news articles, or social media posts.
Bioinformatics: Analyzing genetic data to identify diseases or drug targets.

The Future of SVMs
While new algorithms emerge, SVMs remain a cornerstone of classification tasks. Their interpretability, efficiency, and ability to handle complex data make them a valuable tool in the machine learning toolbox. As research progresses, we can expect even more advancements in SVM techniques, solidifying their place as champions in the classification arena.
Thank you for reading till here. If you want learn more then ping me personally and make sure you are following me everywhere for the latest updates.
Yours Sincerely,
Sai Aneesh




