



Imagine a machine that can understand human language as well as we do. That's the dream behind advancements like Transformers and BERT! Buckle up, because we're about to dive into this fascinating world.
TLDR: Transformer models and BERT have revolutionized language modeling in the past decade. Transformers use attention mechanisms to improve performance in machine translation, while BERT is a powerful bidirectional encoder model that can handle long input context and perform various NLP tasks.
The Transformer Architecture: A Game Changer
Think of traditional language models like a conveyor belt. Words are fed in one by one, processed, and an output is generated. But transformers are different. They can analyze all the words in a sentence simultaneously, understanding the relationships between them. It's like having a super-powered brain that can juggle multiple meanings at once.
Benefits of Transformers:
Long-range dependencies: Transformers can capture how words far apart in a sentence can influence each other. For example, in "The quick brown fox jumps over the lazy dog," "quick" modifies "fox" even though they're separated by other words.
Parallelization: Processing words simultaneously makes transformers faster and more efficient.
Flexibility: The transformer architecture can be adapted for various tasks like machine translation, text summarization, and question answering.
BERT: The Power of Bidirectional Learning
BERT, or Bidirectional Encoder Representations from Transformers, takes the transformer architecture a step further. Traditional models process text in one direction (left to right). BERT, however, is bidirectional, meaning it considers both the words before and after a specific word. This allows BERT to develop a deeper understanding of the context and meaning within a sentence.

What can BERT do?
Understand complex sentences: BERT excels at tasks like sentiment analysis (identifying positive or negative emotions) and question answering.
Fine-tuning for specific tasks: BERT can be adapted for various tasks by adding a small layer on top of the pre-trained model. This makes it a powerful tool for a wide range of applications.
This is just a glimpse into the world of transformers and BERT! There's a lot more to explore, but hopefully, this gives you a foundational understanding of these exciting advancements in Natural Language Processing.
We explored the basics of BERT (Bidirectional Encoder Representations from Transformers) in the previous piece. Now, let's delve deeper into its inner workings and see what makes it such a powerful tool in Natural Language Processing (NLP).
The Magic of Bidirectionality:
Imagine reading a sentence blindfolded, only getting glimpses of words one by one. It's hard to grasp the meaning, right? Traditional language models function similarly. BERT breaks free from this limitation. It analyzes the entire sentence at once, just like you reading normally. This allows BERT to consider the context of each word. Here's how it works:
Word Embeddings: Each word in a sentence is converted into a numerical representation, capturing its meaning and relationship to other words.
Positional Encodings: BERT doesn't just see the words, it also knows their position in the sentence. This is crucial because word order matters! "The cat sat on the mat" has a very different meaning than "The mat sat on the cat."
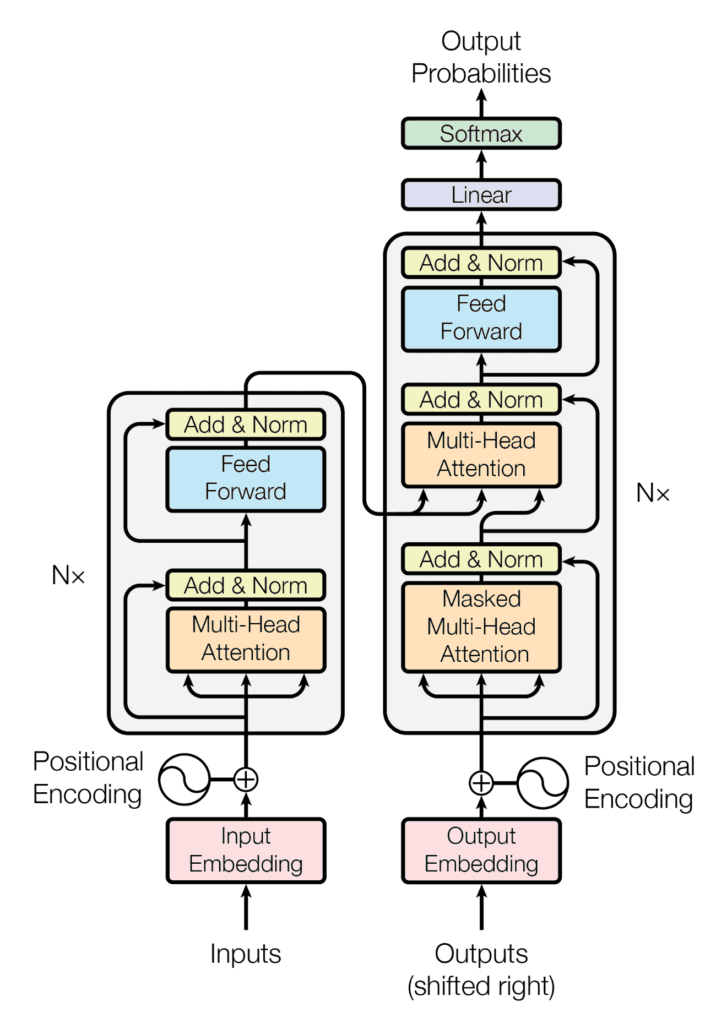
Transformer Magic: The core of BERT is built on the Transformer architecture. It uses two key mechanisms:
Multi-head attention: This allows BERT to focus on different aspects of a word depending on the context. Think of it as simultaneously highlighting the noun function of "cat" and its relation to the verb "sat."
Encoder layers: These layers process the information from the previous step, allowing BERT to build a deeper understanding of the sentence's meaning.
The Power of Pre-training:
BERT isn't trained on a specific task like sentiment analysis. Instead, it's pre-trained on a massive dataset of text, like books and Wikipedia articles. This allows BERT to learn general language patterns and relationships between words. Think of it as building a strong foundation in language before tackling specific tasks.
Fine-tuning for Specific Tasks:
The beauty of BERT lies in its flexibility. Once pre-trained, a small additional layer can be added on top of the core BERT model. This fine-tuning allows BERT to specialize in specific tasks. Imagine adding plumbing fixtures to a pre-built house – the core structure is strong, but you can customize it for a specific purpose, like a kitchen or bathroom.
Here are some examples of tasks BERT excels at after fine-tuning:
Question Answering: BERT can pinpoint the answer to a question within a given passage by understanding the context of both the question and the passage.
Sentiment Analysis: BERT can determine the emotional tone of a piece of text, like positive, negative, or neutral.
Text Summarization: BERT can condense a lengthy piece of text into a shorter summary while preserving the key points.
The Future of BERT:
BERT continues to be a cornerstone in the field of NLP. Researchers are constantly exploring new ways to adapt and improve BERT for even more advanced tasks. As BERT and similar models continue to evolve, they hold immense potential for revolutionizing the way humans and machines interact through language.
Thank you for reading till here. If you want learn more then ping me personally and make you are following me everywhere for the latest updates.
Yours Sincerely,
Sai Aneesh